
What was the one big thing in the last decade?
Answer varies from one person to another. Some say that it is Facebook while some others say that it is Google. But there is a peculiar feature every big company in the past decade has been focussing on, which is personalising one’s experience of Internet. A brief example would be a simple Google Search - “restaurants near me”. Google will give results based on your location because Google knows where you are, where you sleep, where you eat and the list continues. (You can check what Google knows about your location here)
So, why am I ranting about personalisation of Internet?
The answer is pretty simple but there is too much information to fathom in this precise answer - Creating an AI is possible only because of this. Due to much research done in the past decade on creating a personal environment on Internet, it is possible for humans to now “train” the computers to behave in a humanly way.
How do they do it?
By “training” the computer. To make the computer learn, the very first thing that comes to the mind is how to make a computer which can make decisions. Current computers can answer only in streams of 1s and 0s which is rather equivalent to having a conversation with a person which only says Yes or No. Quite obvious that we can’t sustain a conversation. So, how can we program computers to be able to converse?
Sometimes, it’s the nature which leads us onto the right path. In this case, it is our own brain. We try to mimic our own decision making system which is nothing but collection of neurons if we examine it on a simplest level. Computer scientists aptly named this system, neural networks.
Along with revolutionary ideas, there also comes a horde of problems. Neural networks were no exception. The major problem during the initial days was that the technology available wasn’t sufficient to simulate the neural networks. But in the past few years, there is large scale research going on, mainly because we have better computational power.
What researchers are trying to accomplish is to make computers learn without being explicitly programmed on their own!! This is precisely the definition of Machine Learning (ML).
Machine Learning is used to make data models and algorithms which leads to prediction. ML can be as easy as linear regression. And sometimes as complex as Deep Learning. Both Machine Learning and Deep Learning are recent developments in the field of computer science while Deep Learning being the latest as is clear from the infographic.
What is Deep Learning and why are we so excited about it?
The dream of making an AI on a human level is incomplete without DL. Deep Learning attempts to make high level abstractions in data. Sounds all geeky, doesn’t it?
Let’s take an example, suppose, you want to teach computer to recognise your picture. What are steps would you take? The problem which you posed is, given data (like intensity, brightness, RGB level) about a large number of pixels, the job is to correctly identify the person. Sounds tricky? No doubt, the problem is tricky. But enough research is done in this field that the image recognition accuracy by Facebook is reported to be a whopping 97.35%.
I’ll present a simplified version of how Facebook does it. There are two main layers of artificial neurons, the input layer and the output layer. The rest of the layers are called hidden layers. It is hidden layers where the magic happens. All the layers are interconnected to one another with a “weight” between their links. Each layer is programmed to perform a specific task. In the example above, the first layer may do the task of identifying corners. The second layer may do the task of finding edges and so on.
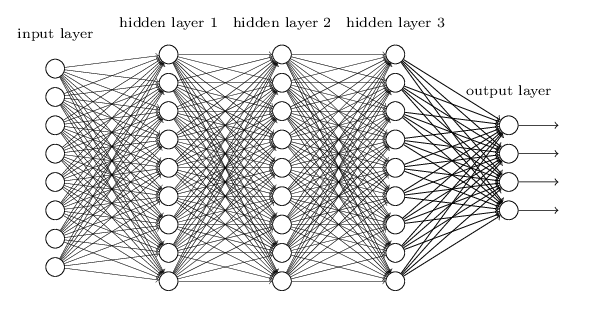
How do neurons know that they are giving correct output?
The neural network is trained using sufficient data and giving feedback to improve its ability to predict. Feedback is implemented in a technique called backpropagation. Output is matched to the feedback given in the training data. The neurons then correct the weight between their connection based on the comparison and then this comparison is propagated backwards until all the weights have been optimised.
The output of any DL algorithm is probabilistic meaning it has a x% chance that the output is correct and (100-x)% chance of not being correct. One natural question arises is that how can we build a perfect AI with human intelligence if the techniques we’re using are probabilistic?
Let’s tackle this question with another example. Suppose, Leonardo da Vinci gave a series to you which goes like: 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024,… and so on. Can you tell me the 36th term?
The answer seems trivial, 2^35, right?
No, the answer is wrong. Leonardo da Vinci made an error in this series. You can check out the series which he gave. The answer he gave is different from 2^35. We, humans, make our judgement with our limited amount of knowledge but computers can have a lot of information. Now that you know about this series, try to make the same decision. Now, you’d say that maybe I’m referring to erroneous series. This example shows that having probabilistic output is a necessity in building AI.
DL is yet far from perfect but we’re making huge headways into making an AI a reality.
As a new research area, deep learning (DL) is taking surprisingly big steps, and not just with the theoretical aspects of it. DL is making huge inroads into applications in fields as diverse as robotics, language translation and gaming, to name a few. Especially, in the field of robotics, deep learning has already started making its impact visible. At the recently held Google I/O, Japan-based SoftBank Robotics handed over Pepper, the humanoid robot, to the researchers at Google in a collaboration aimed at giving rise to the first generation of robots making use of deep learning.

What is it that distinguishes robots from humans?
Robotic behaviour, as opposed to human behaviour, is based largely on a sense-plan-act paradigm, which is based on a considerable amount of processing, based on an ideal model of the world around. Humans, however, do a lot of things reflexively, and much faster than their robotic counterparts, without very little pre-planning.
Take, for example, the act of serving a tennis ball. As long as the ball is in the air, the tennis player continuously keeps track of its motion, and makes small, but fast corrections, so that, in the end, the racket hits the ball perfectly. It is this feedback mechanism that’s instinctively a part of human and animal behaviour that the researchers in the field of robotics are trying to mimic. Although servoing and feedback control have been studied substantially in robotics, the question of how to define the right sensory cue remains exceptionally challenging, especially for rich modalities such as vision. So instead of choosing the cues by hand, we can program a robot to acquire them on its own from scratch, by learning from extensive experience in the real world. In the process, they make use of deep convolutional neural networks (CNNs), and continuous feedback.
Google has been extremely proactive in investing in DL research. They are known to be exploring methods of integrating deep learning into their recently developed self-driving cars. It is believed that the use of such techniques are going to improve image recognition substantially. Another research group (at UC, Berkeley) has reportedly developed a robot that can learn to walk on its own, just like a human child. This robot, aptly named Darwin, is hopefully just the beginning of the era of ultra-smart robotics.
The days ahead sure promise to be exciting for us robotics enthusiasts!